Simple
Linear Regression
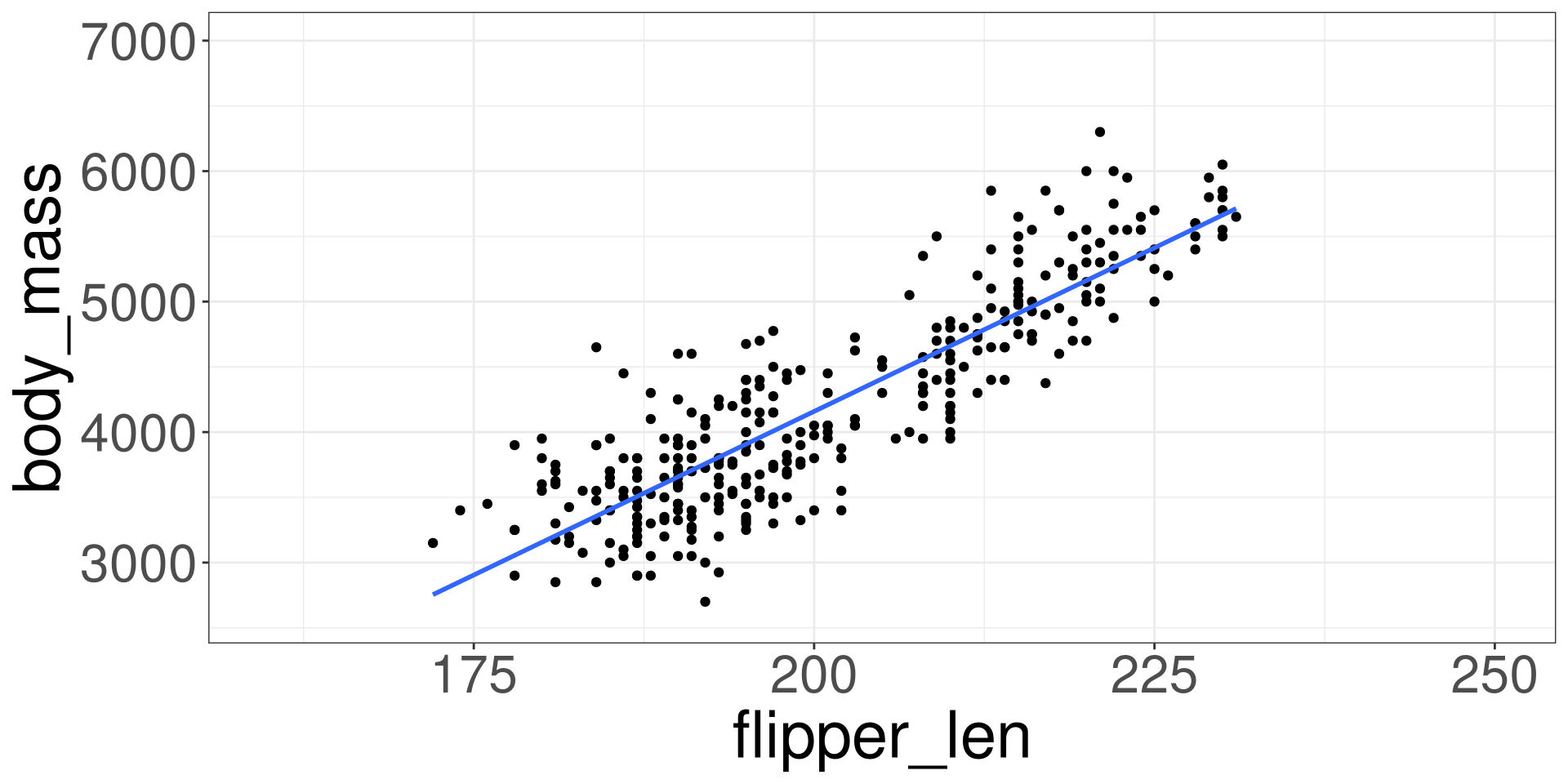
Palmer Penguins Data
Variables of Interest
flipper_len: Flipper Length in millimetersbody_mass: Body mass in grams

Modeling Variation
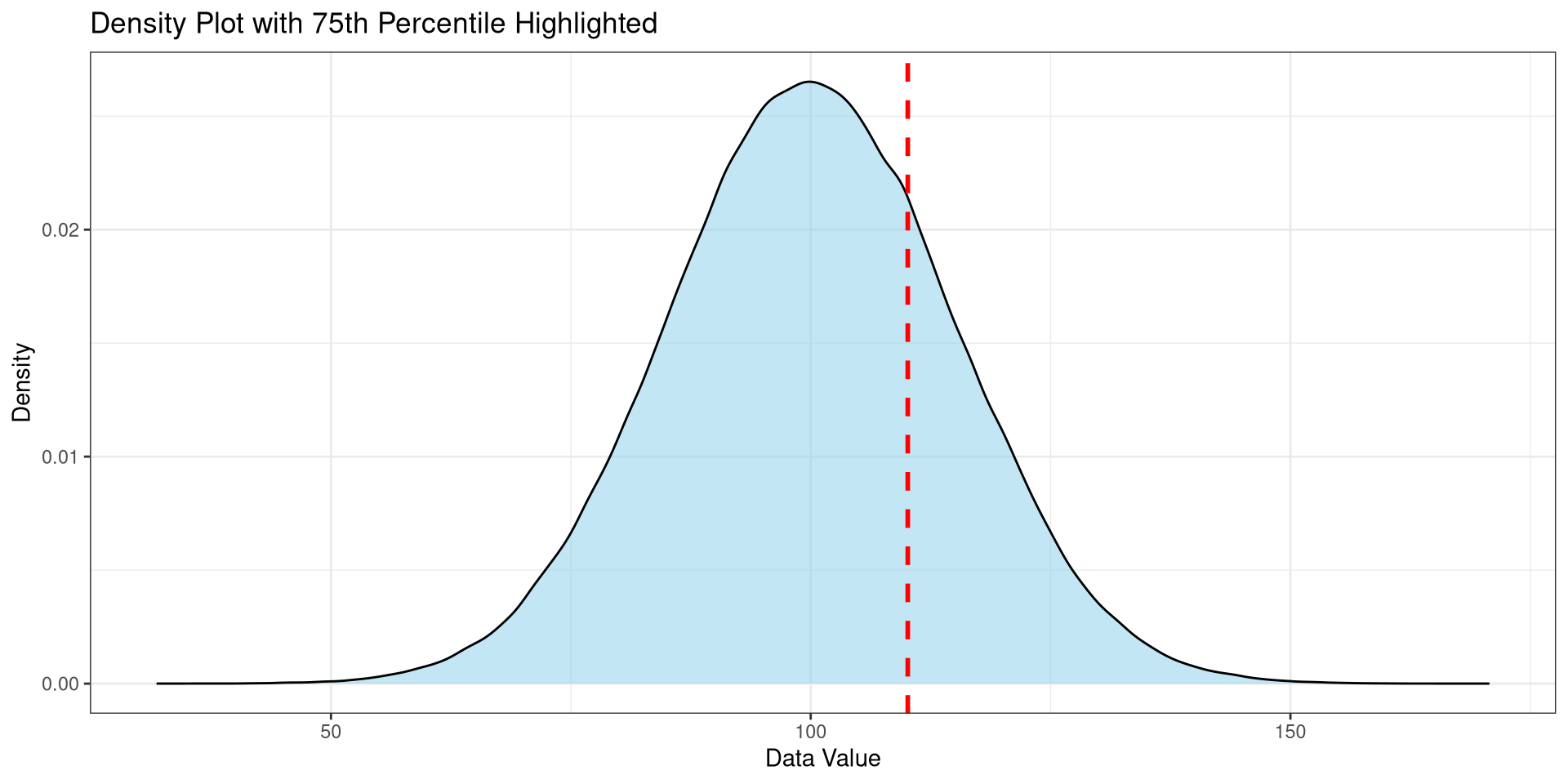
Modeling Variation with \(\bar X\)
Modeling with a Numerical Variable
Modeling with a Numerical Variable
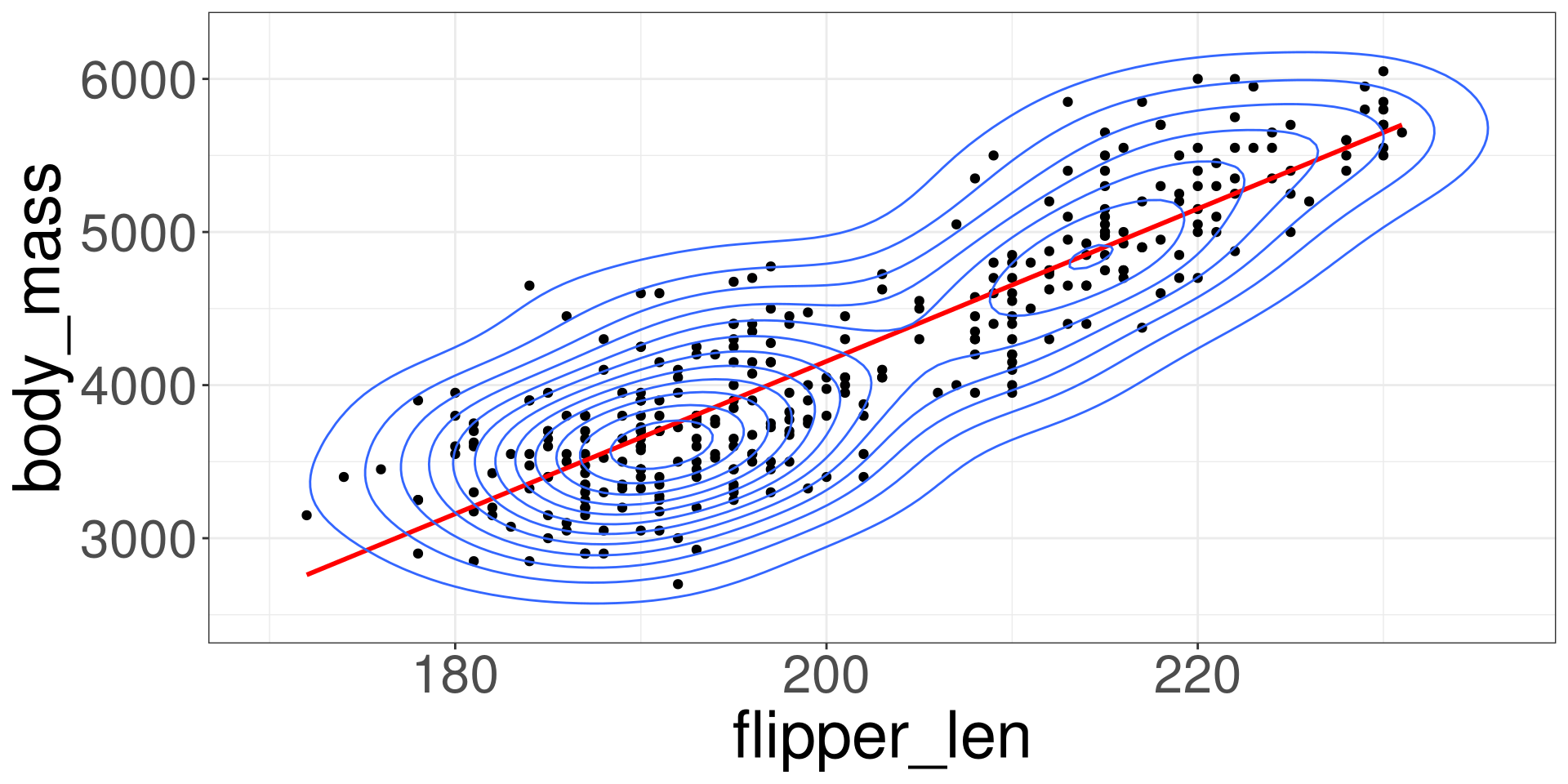
A Simple Model
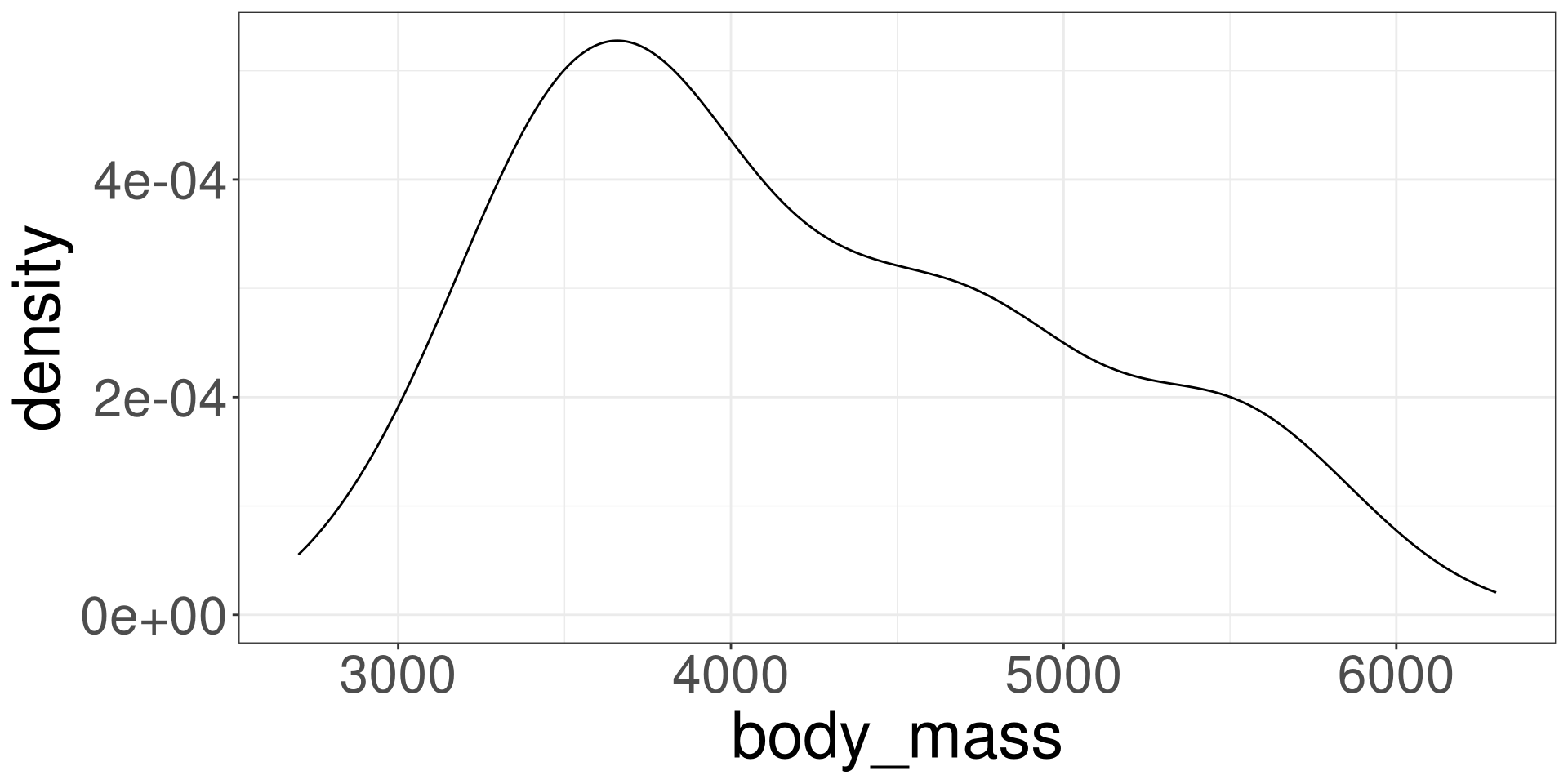
Visualize
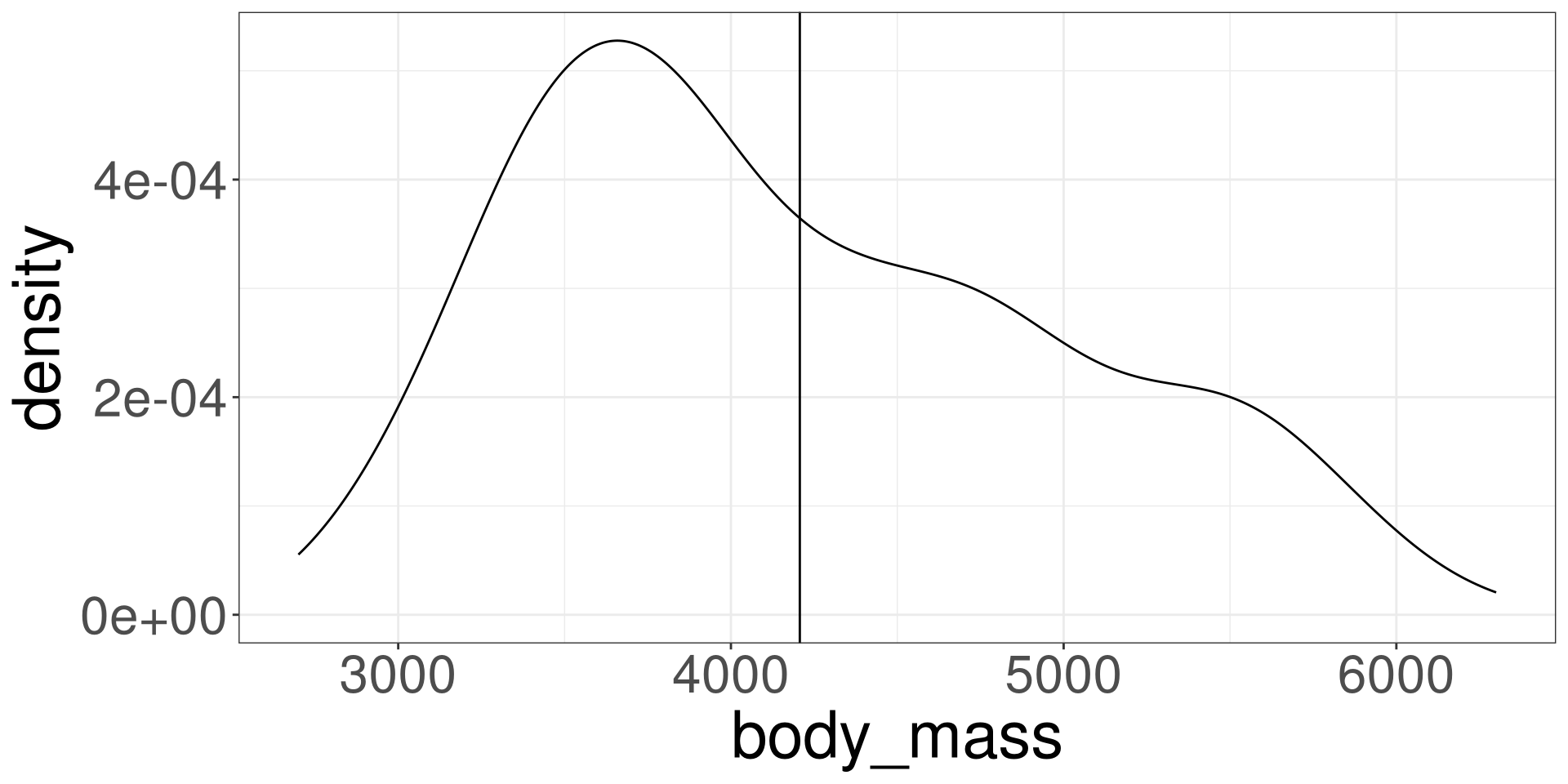
Visualization
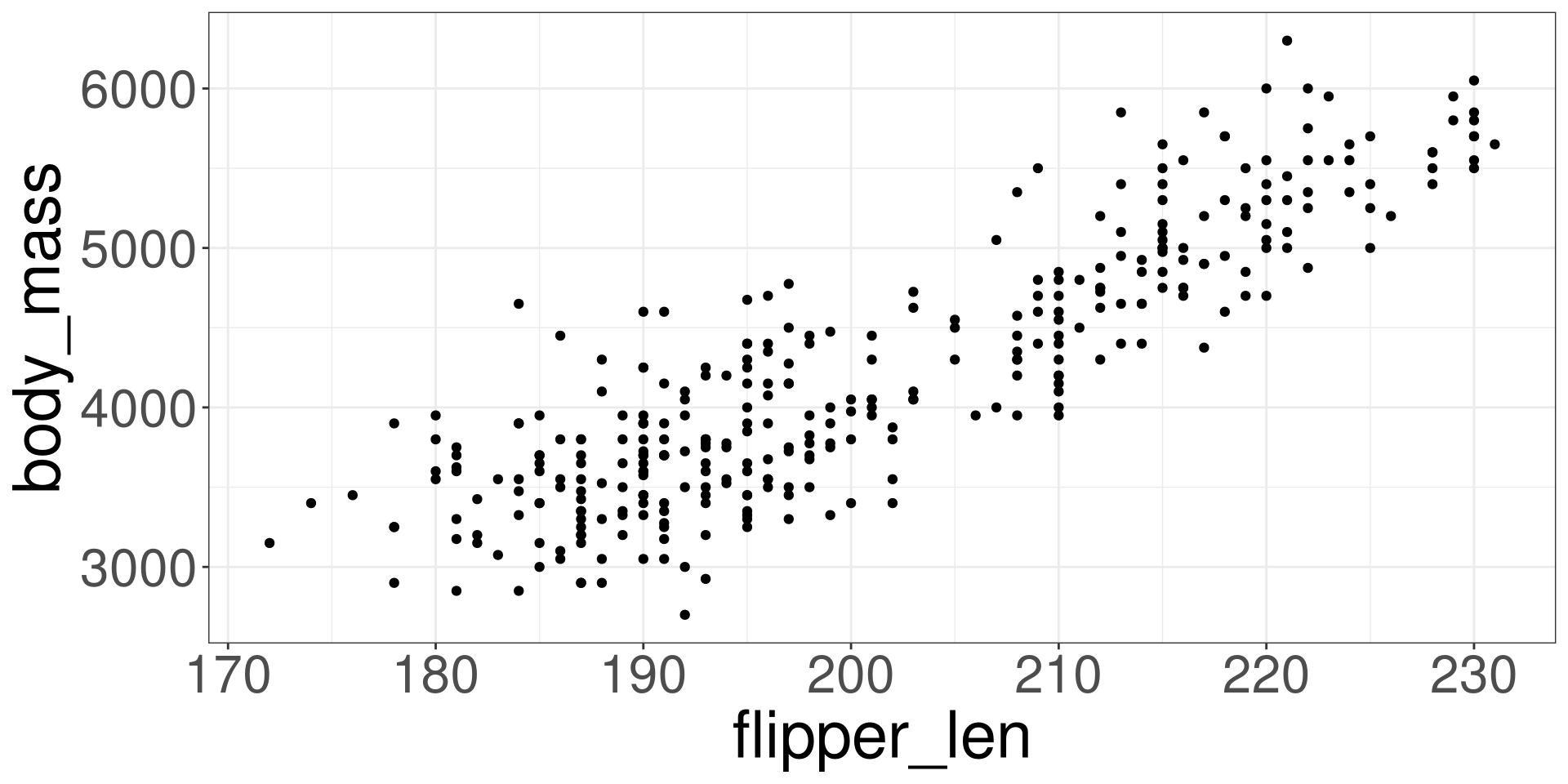
Scatter Plot
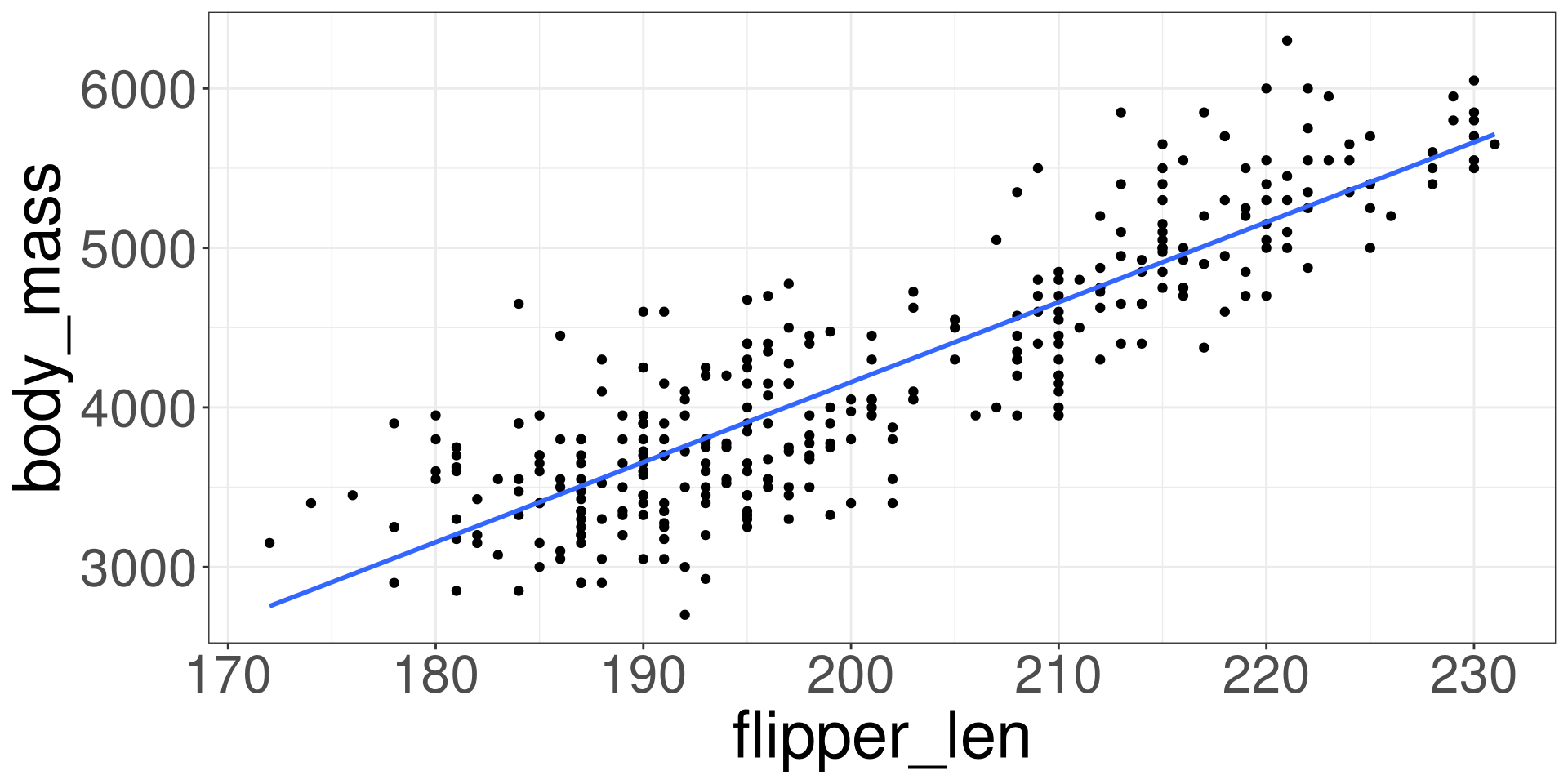
Imposing a Line
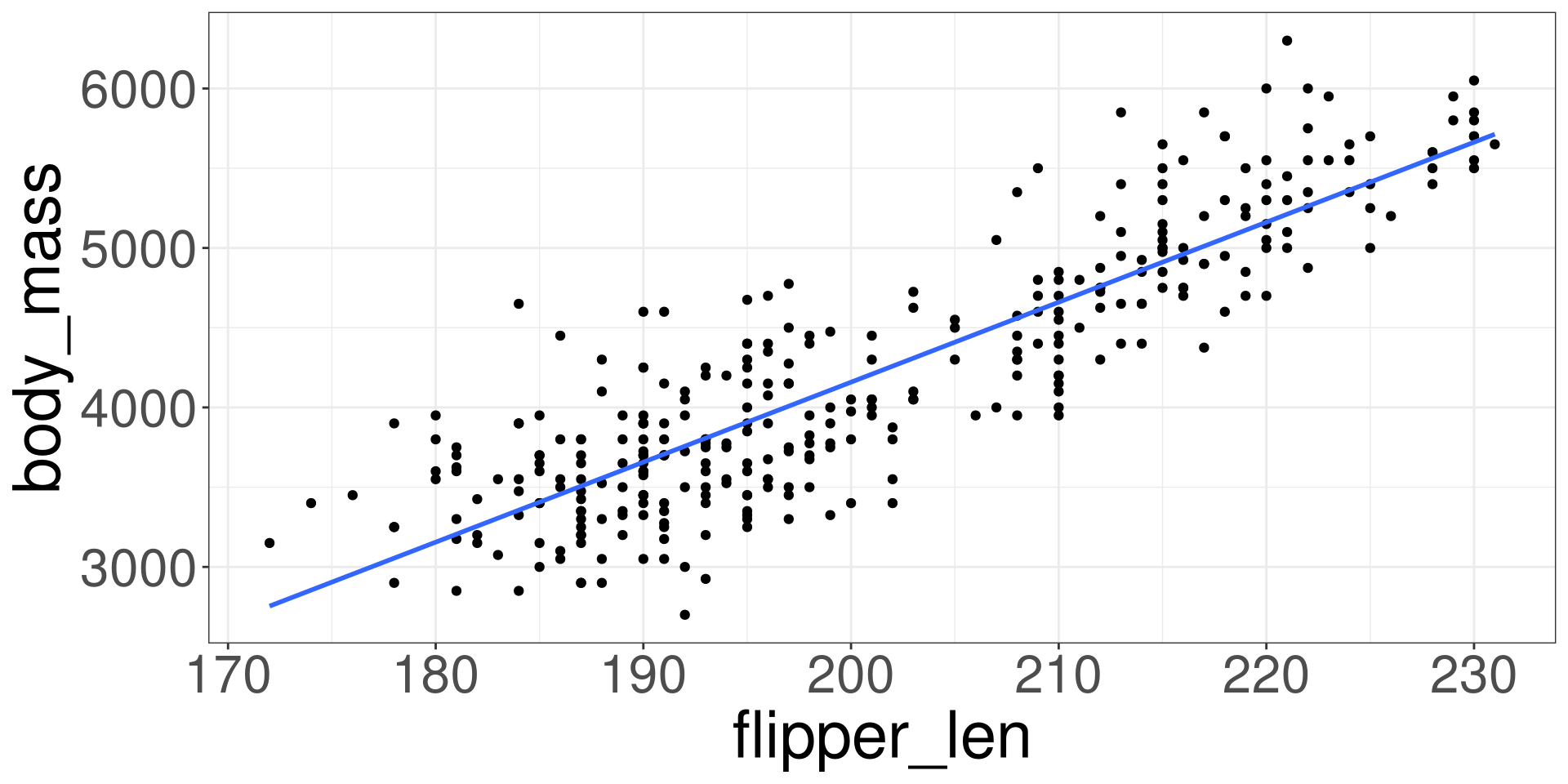
Extrapolation
Code